Performance is one of the tent poles of aws-lite. We take it seriously because we want your applications to be as fast possible.
As such, we regularly test and publish open, reproducible, real-world metrics for every key aspect of performance, comparing aws-lite to AWS’s own aws-sdk (v2) and @aws-sdk (v3). Learn more and view source at the aws-lite performance project on GitHub.
We currently track individual and aggregated performance benchmarking the following AWS service clients: DynamoDB, S3, IAM, CloudFormation, Lambda, and STS.
In addition to publishing our source, raw data, and final results, we believe it’s important to share the details of our performance testing methodology, too. Learn more here.
Coldstart latency measures the impact of each SDK on AWS Lambda coldstarts – the pre-initialization phase where your code payload is loaded into the Lambda micro VM.
In these stats we expect to see lower values for either very small code payloads (such as aws-lite), or scenarios where we are using the AWS SDK included in the Lambda image (e.g. @aws-sdk v3 raw in nodejs20.x). Coldstart latency increases as code payload sizes increase; this is often observed with bundled SDKs.
Initialization latency measures the impact of each SDK on the initialization phase of the Lambda lifecycle, including static analysis and execution of any code outside the scope of the Lambda handler.
Here we expect to see relatively similar values, as the performance benchmark has very little static code or init-time execution.
Peak memory consumption measures each SDK’s peak memory usage throughout import / require, instantiation, read, and write.
To make it easier to assess the memory impact of each SDK, the graph is presented as a value over (thus, not including) the Lambda Node.js baseline. Baseline memory consumption would be expected to include Node.js itself, Lambda bootstrap processes, etc. The memory baseline used always corresponds to the equivalent peak memory of the control test (e.g. aws-lite peak memory p95 - control peak memory p95 = peak memory over baseline p95).
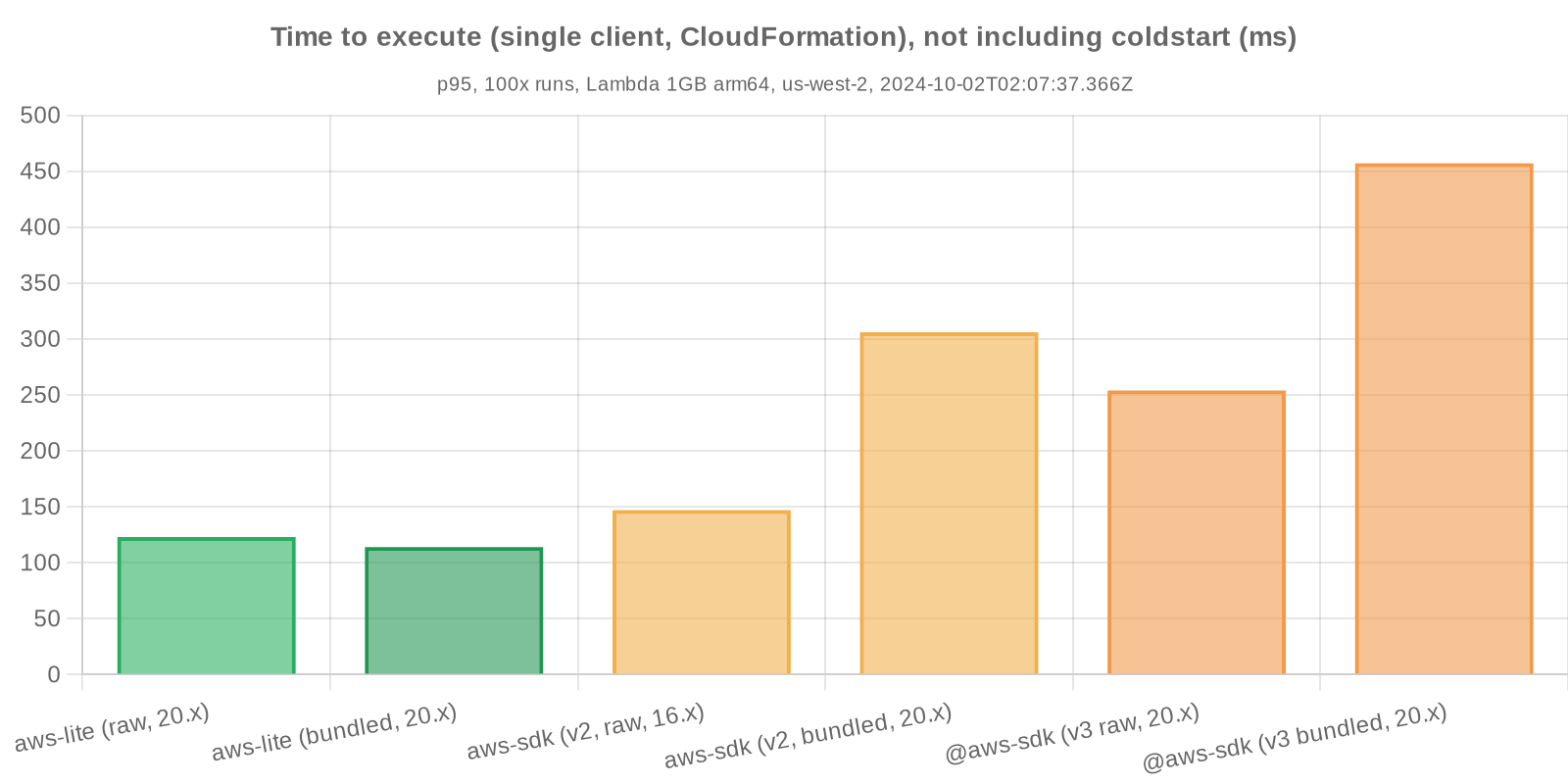
Time to respond measures the total execution time of each SDK, not including coldstart or initialization. In real-world usage, Lambda coldstarts are usually less common than warm invocations, so this metric illustrates the most common case for most applications.
Results below show aggregate data for sequentially executing all six tested clients, followed by individual client response times. (Detailed client statistics can be found here.)
Note: Ideally, response times should be sub-1000ms to ensure fast responses in customer hot-paths. However, the aggregate benchmark simulates importing, instantiating, reading, and writing from six different AWS services in a single execution. When authoring customer-facing business logic, one should ideally utilize fewer services and/or calls to maintain a high degree of customer performance.
Total time to respond measures the total execution time of each SDK, including coldstart or initialization. In real-world usage, this metric represents a normalized “worst case” response time.
Note: Ideally, response times should be sub-1000ms to ensure fast responses in customer hot-paths. However, the aggregate benchmark simulates importing, instantiating, reading, and writing from six different AWS services in a single execution. When authoring customer-facing business logic, one should ideally utilize fewer services and/or calls to maintain a high degree of customer performance.
Each SDK client is measured on the following criteria:
Import / require - Measurement of the impact of importing / requiring each SDK client.
It is important to note that import / require times are tied to individual services. In real world use your business logic may rely on multiple AWS services – each of which necessitating additional imports, thereby compounding overall response latency.
Ideally, all import / require operations should be sub-100ms to ensure fast responses in customer hot-paths.
Instantiate - Measurement of the impact of instantiating a new SDK client – a necessary step before making any service API calls. Ideally all operations should be sub-50ms to ensure fast responses in customer hot-paths.
Read - Measurement of a simple read operation to a service API. All reads are identical across SDKs.
Write - Measurement of a simple write operation to a service API. All writes are identical across SDKs.
Note: some clients may be read-only, based on the service in question (example: STS).
Total - Measurement of the total latency associated with all the above operations, thereby demonstrating the overall impact of using a given SDK client.
Here we measure the latency associated with listing a single CloudFormation stack’s resources (ListStackResources()), and parsing and returning results.
Here we measure the latency associated with updating a single CloudFormation stack’s configuration (UpdateTerminationProtection()). This method was selected specifically to help limit the impact of stack update latency, which can be highly variable, from benchmarking routines.